
기존 API 호출 방식의 한계
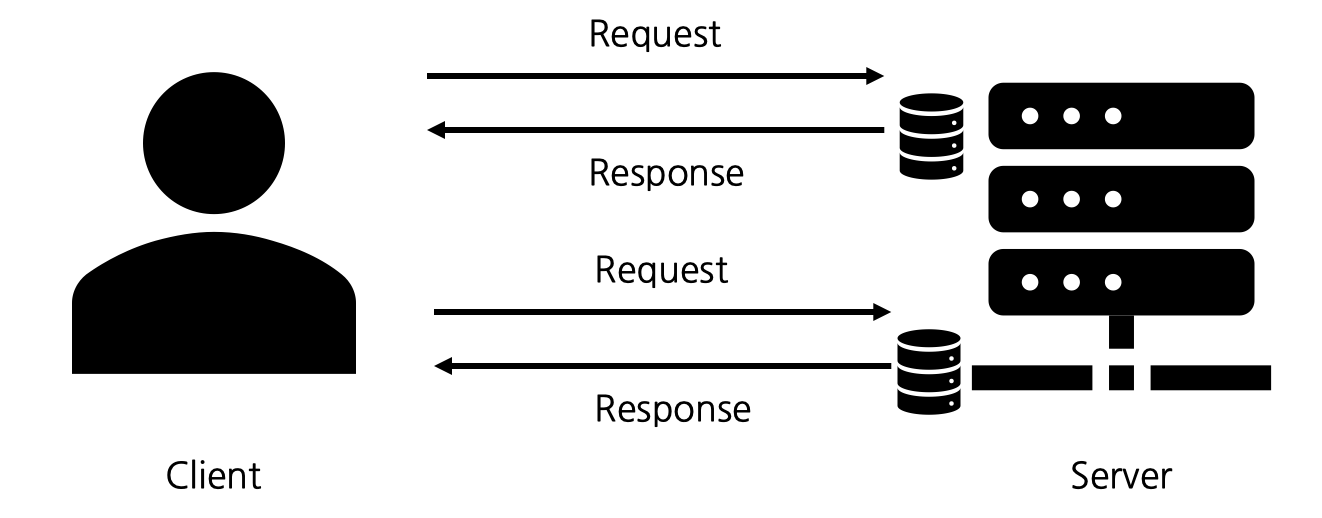
우리는 클라이언트 개발(안드로이드, iOS, 웹)을 하면서 서버와 통신을 해야 할 때 보통 서버가 구현해놓은 API를 호출해 데이터를 보내거나 받아온다. 보통 앱에서 하나의 View를 그리기 위해서는 보통 여러 번 API를 호출해야하고, 호출을 통해 받아온 데이터를 조합해 사용해야 한다. 예를 들어 여러번 REST API를 호출해 하나의 View를 만들어내는 경우를 생각해보자. 앱의 페이지가 복잡해질 수록 많은 호출을 해야하고 데이터 조합을 위해 순차적인 처리가 들어가야 하는 경우가 많아지기 때문에 데이터를 조합하는 것은 매우 복잡해진다.

이를 편하게 하기 위해 데이터 흐름을 만들고 해당 흐름에 순차 처리 로직을 위한 로직을 넣는 방식의 프로그래밍이 많이 사용되었다. 대표적인 것은 Rx와 Coroutine의 Flow 등이 있다. 하지만 flatmap이나 map 등으로 데이터를 변환시키는 것은 결국 우리가 하나의 페이지를 그리기 위한 데이터를 조합하는 것을 클라이언트 단에서 처리해주어야 하기 때문에 클라이언트 단의 로직이 복잡해지는 문제가 있다. 로직이 복잡해지는 것은 유지보수가 어려워진다는 뜻이다.
기존의 REST API나 다른 API 호출 방식은 이 문제를 해결하지 못한다. 기존 API들에서는 사용자는 서버에서 정의한 데이터 구조만을 한 번에 하나씩 가져올 수 있기 때문이다. 이를 해결하기 위해서는 앱 단에서 직접 뷰에 보여질 쿼리를 만들어 모든 데이터를 한 번에 가져와야 하기 때문이다.
GraphQL과 문제 해결
GraphQL은 클라이언트에서 자기에 필요한 데이터만을 쿼리할 수 있도록 하여 위의 문제를 매우 직관적이고 깔끔하게 해결한다. 이를 위해 GraphQL은 클라이언트에서 사용할 Query Language를 정의한다. 클라이언트가 자신에게 필요한 데이터에 대한 Query를 선언해 GraphQL에 넘기면 GraphQL은 Query를 해석해 서버에서 필요한 데이터를 가져온 후 클라이언트에 해당 쿼리에 대한 데이터를 반환한다.
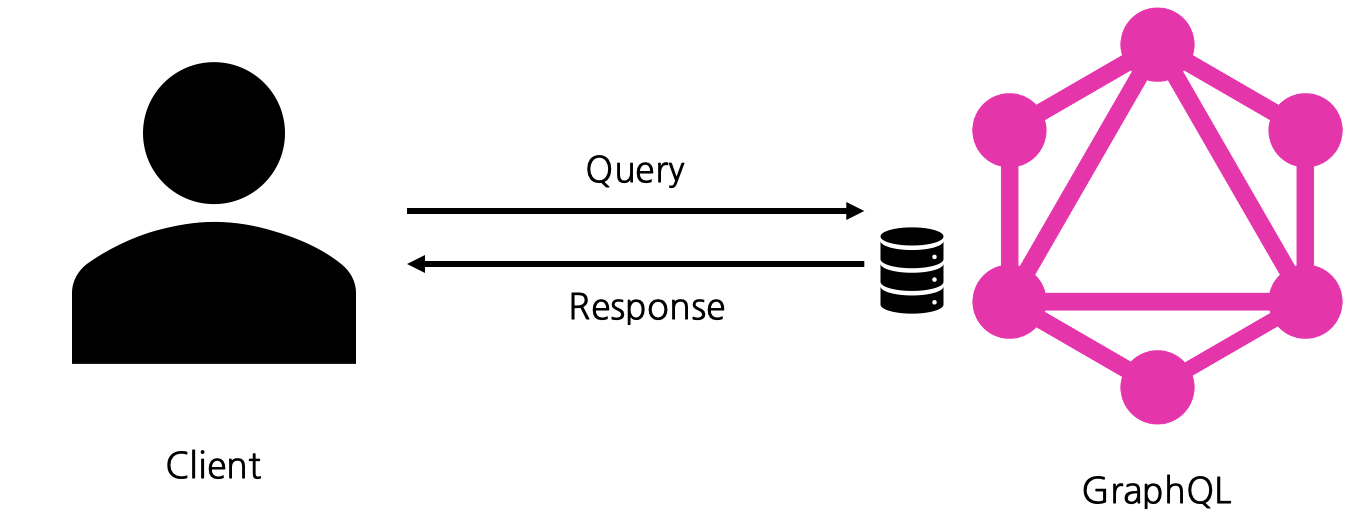
예를 들어 id가 에 따라 저자의 이름과 이메일을 가지고 오고 싶다면 다음과 같이 쿼리를 날리면 된다.
query Author($id : Int) {
author(id: $id){
name
email
}
}
만약 여기서 주소도 가져오고 싶다면 한 줄을 추가하면 된다.
query Author($id : Int) {
author(id: $id){
name
email
address
}
}
즉, GraphQL은 다른 Query Language인 SQL 등과 같이 쿼리를 선언하면 해당 값에 맞는 데이터를 가져온다. 이는 최근 선언형 패러다임이 절차적으로 쿼리를 처리하는 것이 아닌 선언적으로 쿼리를 처리함으로써 더욱 직관적으로 어떤 데이터가 오는지를 알 수 있게 된다.
위에서 말하는 것만 들어보면 GraphQL은 완벽하다. 기존에 10번 호출해서 데이터를 조합해야 하는 것을 단 한 번의 호출로 해결 할 수 있다니 엄청난 기술이다. 하지만 뭔가 많은 것이 생략된거 같지 않은가? 아래에서 GraphQL의 한계에 대해 살펴보자.
GraphQL의 구조와 한계
클라이언트에서 쿼리를 선언하면 데이터를 절차적으로 처리하는 것은 누가 하는가? SQL은 RDB가 해당 역할을 수행하는데 GraphQL은 도대체 누가 그 역할을 할까? 바로, 서버와 클라이언트 사이에 GraphQL이라는 Service Broker 레이어가 더 들어가고 이 GraphQL에서 절차적으로 처리를 수행한다. 즉, GraphQL을 사용하기 위해서는 서버와 클라이언트의 중간에 GraphQL이 레이어로 하나 더 있다고 보아야 한다. 클라이언트는 서버를 알 필요가 없이 GraphQL 레이어랑만 통신함으로써 데이터를 가져오는 것이다. 즉, 기존에 클라이언트에서 데이터를 조합하던 역할이 GraphQL로 옮겨지는 것이다.

이는 결국 역할의 분리이다. 우리가 모듈을 만드는 이유도, 라이브러리를 만드는 이유도 모두 역할의 분리이다. 하지만, 모듈로 역할을 분리하면 분리할 수록 개별 모듈의 유지보수는 쉬워지지만 구현은 복잡해진다. 이 때문에 간단한 앱은 단일 모듈로 만들고, 앱의 크기가 커지면 커질 수록 모듈을 분리하는 것이다. 마찬가지로 GraphQL을 만들면 클라이언트(앱)에서는 통신 로직의 구현이 편해지지만, 그만큼 서버에서는 일이 가중된다. 따라서 앱의 규모, 사이즈에 따라 GraphQL을 도입할지 말아야 할지를 결정하는 것이 옳다.
그럼에도 GraphQL은 좋다
위와 같은 이유에도 여전히 GraphQL은 좋다. GraphQL을 사용하면 유지 보수는 물론 확장이 용이한 API를 구현할 수 있으며, 이로 인해 이중 삼중으로 작업해야 하는 부분이 줄어든다. 또한 GraphQL이 있으면 서버에서 할 수 있는 일을 스키마 단위로 파악할 수 있고 필요한 정보를 유연하게 가져올 수 있다. 또한 여러번 요청하는 것을 한 번으로 줄임으로써 서버의 리소스를 최적화 할 수 있고, 클라이언트의 요청에 대한 부담이 줄어들게 된다.
이번 시리즈에서는 GraphQL에서 쿼리를 날리는 방법, 단위 등을 전체적으로 살펴보고자 한다.
